Upward assignment in Ruby
Ruby has had leftward assignment (x = 4) since its first public release, and a few years ago it added rightward assignment (4 => x). Then at RubyConf 2021, Kevin Kuchta explained how to abuse Ruby features to build a downward assignment operator (yes, this really works):
4
‖
x
It’s a good talk that I recommend watching, and if you get to the end you’ll see he poses a further challenge: build an upward assigment operator:
x
⇑
4
A few days ago, I had an idea for what it might take to get this working, and then I did. It’s brittle, fragile, and a pile of hacks, but it does work. Doing this gave me practical experience with several Ruby features I haven’t used before, and although I’ve watched Kevin’s talk several times, I learnt far more while writing my own code.
Grab a hot drink, a biscuit, and let’s dive in. This is a long one.
Looking in the “wrong” direction
To implement downwards assignment, Kevin is looking up.
He uses TracePoint and Ripper to scan each line of code for identifiers, which include both variable names and the so-called “vequals” operator (denoted ‖).
When he finds a vequals operator, he looks up to the previous line to see if there’s a value above it, and remembers that value in a cache. (“On line 7, from characters 3 to 7, there’s a value "whale"”)
When he finds a variable name, he looks up to the previous two lines to see if (1) the variable is below a vequals operator and (2) he knows what value that vequals operator is assigning. If he finds a value, he assigns it to the variable. The rest of the program proceeds as normal, unaware that this variable was assigned in an unusual way.

Unfortunately we can’t use this trick for upwards assignment, because Ruby will never get to what I’m calling the “uequals” operator (denoted ⇑). It will fail on the line above, because it doesn’t know about the variable we’re trying to assign:
x # => undefined local variable or method `x' (NameError)
⇑
4
But if Kevin can assign downwards by looking up, can we assign upwards by looking down?
Here’s my idea: we scan each line of code for variable names, and any time we see one, we’ll look down to the next line for a uequals arrow. If we find one, we’ll look down to the next line after that, to see what value we should assign:

This is pretty similar to what Kevin did, so we can reuse a lot of the same tools. I’ve broken this down into a couple of steps:
- run code just before every line
- look for variables, upward assignment arrows, and values
- actually assign the variables
We’ll need to (mis)use several Ruby tools along the way, including TracePoint, Ripper, and bindings. Let’s dive in.
Run code just before every line
TracePoints are a Ruby feature that let you run code in response to certain events in your program – for example, at the start/end of a class definition, when exceptions are thrown, or on every method call. It can be a useful debugging tool… and it can be other things too.
To create a tracepoint, you write Tracepoint.new and the name of the event you want to trace, then a block which takes a single argument. (I’ll explain what the argument is shortly.) Once you’ve created your tracepoint, you have to explicitly enable it before anything happens. Here’s a simple example, which prints a message on every line of code:
tracepoint = TracePoint.new(:line) do |tp|
puts "calling the tracepoint!"
end
tracepoint.enable
puts 'Hello world!'
This is what gets printed:
calling the tracepoint!
Hello world!
Notice that "calling the tracepoint!" is printed before "Hello world!" – tracepoints run just before the triggering event, not after. This is how we’re going to make upwards assignment work: when we find a line with an upwardly-defined variable, we’ll define it inside the tracepoint. This will run before Ruby runs the original line, so we’ll avoid the NameError we’re currently getting.
(Sidebar: I was testing the code snippets in this post using irb, and the tracepoint was triggered nearly 700 times. REPLs are complicated!)
The single argument passed to the block has some information about the event that triggered the tracepoint, which includes the line number and path.
tp.lineno # => 7
tp.path # => example.rb
This information is meant to be useful for debugging. For example, we can use build a simple tool to measure line coverage:
$covered_lines = []
coverage_tracker = TracePoint.new(:line) do |tp|
$covered_lines << [tp.path, tp.lineno]
end
coverage_tracker.enable
puts 'Hello world' # => 'Hello world'
puts $covered_lines.inspect # => [['coverage.rb', 9], ['coverage.rb', 10]]
So far, so sensible. This is the sort of task that TracePoint is usually used for, and I think it’s cool that this sort of power is built into Ruby core.
This power does have limits: it doesn’t know the source code of the line that’s about to run, which is pretty important for what we’re doing:
tp.line # => NameError
but that’s not actually an issue, because we have all the information we need to get it ourselves, and none of the restraint that would stop us:
# note: tracepoint line numbers are 1-indexed, so they match what you
# see in your text editor, but File.readlines is 0-indexed.
line = File.readlines(tp.path)[tp.lineno - 1]
Reading the entire file on every line is very inefficient and it breaks in a REPL, but it works – and if we can read one line of code, there’s nothing to stop us reading the next line, and the next line after that. Now we have access to the currently-running source code, we need to inspect it for variables, upward assignment arrows, and values.
Parse Ruby code with Ripper
If we have a line of source code, we could look for arrows with something like String.index:
'puts "Hello world"'.index('⇑') # => nil
'⇑'.index('⇑') # => 0
'puts "upward assignment uses ⇑"'.index('⇑') # => 29
But this will find arrows anywhere in the line, including in places where it’s not an operator – like in the third example, where it’s found an arrow in a string. To do this properly (and of course we care about doing things properly), we need to be able to parse Ruby source code.
Fortunately, Ruby has a built-in mechanism for doing this, in the Ripper module. The method we want here is Ripper.lex, which breaks code into a series of tokens. Here’s a simple example:
require 'ripper'
Ripper.lex('x = 12 + 34')
# => [[[1, 0], :on_ident, 'x', EXPR_CMDARG],
# [[1, 1], :on_sp, ' ', EXPR_CMDARG],
# [[1, 2], :on_op, '=', EXPR_BEG],
# [[1, 3], :on_sp, ' ', EXPR_BEG],
# [[1, 4], :on_int, '12', EXPR_END],
# [[1, 6], :on_sp, ' ', EXPR_END],
# [[1, 7], :on_op, '+', EXPR_BEG],
# [[1, 8], :on_sp, ' ', EXPR_BEG],
# [[1, 9], :on_int, '34', EXPR_END]]
The result is an array of arrays, whose format is [[lineno, column], type, token, state]. Each entry is a single token.
The lineno and column are pretty self-explanatory, and token is the source code for this token. I’m not sure what all the values for type and state are, but I’m not too concerned – I don’t think I care about state at all, and not all the values of type will be interesting to me. In this example, :on_ident and :on_int are the two that look most useful.
You need to be a bit careful of the column returned by Ripper.lex: it’s counted based on bytes, not characters, so non-ASCII characters can throw it off. For example, an identifier like Münze would take up 6 spaces, not 5. (I was tipped off to this by a comment in Kevin’s vequals code.)
We can see this by comparing two lines that do/don’t use Unicode characters:
puts "The lions are #{lowen}, the birds are #{vogel}, the owls are #{eule}"
# ^^^^^^^^ ^^^^^^^^ ^^^^^^^^
# 22..27 46..51 69..73
puts "The lions are #{löwen}, the birds are #{vögel}, the owls are #{eule}"
# ^^^^^^^^ ^^^^^^^^ ^^^^^^^^
# 22..27 47..52 71..75
Notice how the column as reported by Ripper.lex gradually diverge, even though the characters look visually aligned. Fortunately we have access to the original text in token, so we can just track the column manually.
By breaking the line into tokens with Ripper.lex, and filtering for tokens which have type :on_ident, we can find the identifiers – which include both the variable names and the arrows.
def find_identifiers_in_line(source_code)
lexed_line = Ripper.lex(source_code)
column = 0
result = []
lexed_line.each do |_positions, type, token, _state|
if type == :on_ident
result << {
token: token,
range: (column..column + token.length)
}
end
# track the column manually
column += token.length
end
result
end
puts find_identifiers_in_line('x = y + 1')
# [{:token=>'x', :range=>0..1},
# {:token=>'y', :range=>4..5}]
puts find_identifiers_in_line('name = "Alex"')
# [{:token=>'name', :range=>0..4}]
puts find_identifiers_in_line('⇑')
# [{:token=>'⇑', :range=>0..1}]
Each identifier has two keys: :token is the source code, and :range tells us which characters it appears on in the line.
We can put this in a tracepoint, and Ruby will print a list of identifiers it finds on every line:
id_printer = TracePoint.new(:line) do |tp|
line = File.readlines(tp.path)[tp.lineno - 1]
puts find_identifiers_in_line(line)
end
Now we need to work out which identifiers are interesting.
Finding the upward assignment arrows
We can put together what we’ve done so far to find all the identifiers on a line that have an upward assignment arrow below them:
arrow_finder = TracePoint.new(:line) { |tp|
line = File.readlines(tp.path)[tp.lineno - 1]
identifiers = find_identifiers_in_line(line)
arrow_line = File.readlines(tp.path)[tp.lineno]
# if there's no next line, we're at the end of the file
# there definitely isn't an arrow below us!
unless arrow_line.nil?
arrows =
find_identifiers_in_line(arrow_line)
.filter { |id| id[:token] == '⇑' }
identifiers.each { |var|
arrow_below =
arrows
.filter { |id| var[:range].cover? id[:range] }
.last
# If there's no arrow below us, we can move on to the next identifier
unless arrow_below.nil?
puts "L#{tp.lineno} variable #{var[:token]} has an arrow below it"
end
}
end
}
arrow_finder.enable
x
⇑
4
# L49 variable x has an arrow below it
We read the current line and the next line; if there is no next line, then we can bail out early – there’s definitely no arrow below us! For each identifier, we look for identifiers on the next line which (1) are the upward arrow and (2) overlap with this identifier.
This uses ranges, which are a new-to-me feature of Ruby. I particularly like the cover? method, which tells you if one range is contained by another. (So 0..3 covers 1..2, but not the other way round.) It’s not complicated, but it can be fiddly to get the inequalities the right way round, and a named function makes it easier and clearer.
This finds the last arrow operator that’s under an identifier, so that if a identifier sits above multiple arrows, the rightmost arrow takes precedence:
best_number_of_cats
⇑ ⇑ ⇑ ⇑ ⇑ ⇑
0 1 2 3 4 5
There are lots of other edge cases we might want to think about here if we were designing it properly, but let’s pretend silly things like this can’t happen, and move on.
Find the value below each arrow
Now we’ve found an arrow, we need to know what value is beneath it (if any). A value is anything that we can assign to a variable – a string, a number, another variable. There are lots of different types of value; for now I’m going to just handle a few, but you could extend it to find more.
We can find values with a lightly modified variant of find_identifiers_in_line:
def find_values_in_line(source_code)
lexed_line = Ripper.lex(source_code)
column = 0
result = []
lexed_line.each do |_positions, type, token, _state|
if type == :on_ident || type == :on_tstring_content || type == :on_int
result << {
:type => type,
:token => token,
:range => (column..column + token.length)
}
end
# track the column manually
column += token.length
end
result
end
puts find_values_in_line('x = y + 1').inspect
# [{:type=>:on_ident, :token=>'x', :range=>0..1},
# {:type=>:on_ident, :token=>'y', :range=>4..5},
# {:type=>:on_int, :token=>'1', :range=>8..9}]
puts find_values_in_line('name = "Alex"').inspect
# [{:type=>:on_ident, :token=>'name', :range=>0..4},
# {:type=>:on_tstring_content, :token=>'Alex', :range=>8..12}]
Then we drop this into our tracepoint, and look below the arrow we found in the previous step:
value_finder = TracePoint.new(:line) { |tp|
…
unless arrow_below.nil?
value_line = File.readlines(tp.path)[tp.lineno + 1]
unless value_line.nil?
values = find_values_in_line(value_line)
value_below =
values.find { |v| v[:range].cover? arrow_below[:range] }
unless value_below.nil?
puts "L#{tp.lineno} variable #{var[:token]} should be assigned to #{value_below}"
end
end
end
…
}
value_finder.enable
x
⇑
4
# L79 variable x should be assigned to {:type=>:on_int, :token=>'4', :range=>0..1}
This is quite fragile – for example, if the arrow is above the opening/closing quotes of a string, it won’t find the string, and it won’t capture values that span multiple lines, but it’s enough to get something basic working.
Now we know what the name of the variable, and the value it should have, we just need to assign it. Simple, right?
Assign variables (or not) using bindings
This turned out to be the hardest bit, and I still don’t fully understand what Ruby’s doing here – but I got something working, and I’ll explain as best I can.
When you’re inside a tracepoint, you have access to something called a binding (which is an instance of the Binding class). This contains a bunch of context about the current state of the program, including any variables and methods. You can imagine this would be very useful when you’re debugging.
tp.binding # => #<Binding:0x0000000143157090>
tp.binding.local_variables # => [:shape, :sides, :tracepoint]
These bindings don’t just appear in tracepoints; you can get to them from anywhere in Ruby. Whenever you call the globally available binding method, you get a new binding with a copy of the current context, which you can then pass around like any other value. This gives us a way to break a bunch of rules.
Here’s an example of a program that doesn’t work:
def greet(name)
first_name, last_name = name.split()
puts "Hello #{first_name}!"
end
greet('Alex Chan') # => Hello Alex
puts first_name # => NameError
Inside greet I create a variable first_name, but it’s only available inside that function. When the function returns and we’re back in the top-level, I can’t get to any of the variables inside the function. If I try to use first_name, I get a NameError. This is the behaviour we’re used to:
But if I create a binding inside the function, and then return that, now I can can get to that variable in the top-level:
def greet(name)
first_name, last_name = name.split()
puts "Hello #{first_name}!"
binding
end
b = greet('Alex Chan') # => 'Alex Chan'
puts b.local_variable_get(:first_name) # => 'Alex'
The binding holds a reference to the local variables inside the function, and when the binding is returned from the function, we can still get to them. This breaks the usual rules of variable visibility and it’s extremely powerful. And as they say, power is a corrupting influence.
When I first read the docs for the Binding class, I thought maybe I could use the local_variable_set method. You can use it to update the value of an existing variable, and that gets reflected outside the binding:
colour = 'blue'
binding.local_variable_set(:colour, 'red')
puts binding.local_variable_get(:colour) # => red
puts colour # => red
but if you try to set a variable that doesn’t exist yet, it’s only available inside the binding:
b = binding
b.local_variable_set(:shape, 'square')
puts b.local_variable_get(:shape) # => square
puts shape # => NameError
This is rather annoying, because it means we can’t just call tp.binding.local_variable_set inside our tracepoint to create a new variable; we need to do something else. We need to find a way to escape the binding.
Sidebar: speculating about scope
I don’t fully understand why this happens; scope is one of those topics I’ve never quite grokked. This section is quite speculative and might be entirely wrong. It’s my mental model and it seems to fit, but please do let me know if you spot an error.
Here’s my best understanding of what happens: Ruby has “scopes”, which is a collection of variables. Every variable lives in a scope, and you get lots of different scopes in the lifetime of a program: functions, classes, blocks, and so on – they all have different scopes. You can only access, modify, and create variables inside your current scope; you can’t get to variables in other scopes.
Scopes can have references to variables in other scopes, and any changes to the reference affect the variable in the original scope. This is how variables get passed into functions – the function scope gets a reference to the variable in the parent scope. We can see this when a function mutates a variable that gets passed in:
def add_square(shapes)
new_shape = 'square'
shapes << new_shape
end
colours = ['red', 'green', 'blue']
shapes = ['circle', 'triangle']
add_square(shapes)
puts shapes # => ['circle', 'triangle', 'square']
Here’s my mental picture of what’s going on:
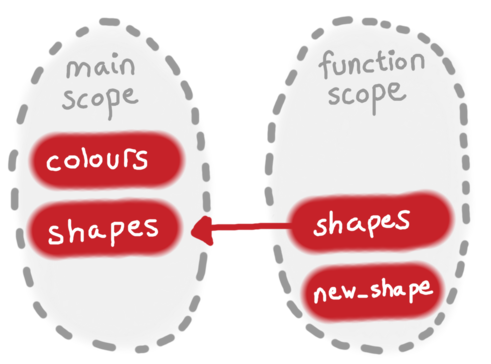
The main scope has two variables: colours and shapes.
When we call the add_square function, it creates a new scope for that function. (More precisely, I think we get a scope for this call of the function – if we called the function a second time, we’d get a brand new scope.) This scope gets a reference to the shapes variable in the main scope, because it was passed in as a parameter.
Inside the body of the function, we modify the value of shapes, and because that’s referring to a variable in the main scope, it gets modified in both the function scope and the main scope.
We’ve also created a variable new_shape. This variable is created in the function scope, and not in the main scope. When the function returns and we go back to the main scope, that variable is no longer accessible (as we saw in the previous example).
Here’s the key bit: I think you get a new scope when you create a binding. The binding scope has references to all the variables in the parent scope, but it’s not the same scope. That means that you can update a variable which came from the parent scope (like updating shapes), but any newly created variables are only created in the binding scope (like new_shape).
We can create new variables in bindings, but they aren’t accessible outside the binding.
Escaping through the receiver
Remember that a binding contains all the context about the program, including both variables and methods. Variables live in the scope, but where are the methods?
Every method in a binding is attached to an object called the receiver:
binding.receiver # => main
This terminology comes from SmallTalk, in which objects would pass messages to each other – one object was the sender, the other the receiver. In Ruby, calling a method on an object is the same as sending a message to the object – and the object is the method’s receiver.
Integer.sqrt(25) # => 5
Integer.send(:sqrt, 25) # => 5
What’s interesting here is that the receiver is outside the binding, so if we create a new method on the receiver, it’ll be available outside the binding. And we can create new methods on any Ruby object with define_singleton_method:
binding.receiver.define_singleton_method(:greet) { puts 'Hello world' }
greet # => Hello world
We can also do this on the binding we get inside a tracepoint, and because the tracepoint runs before the line, the new method is available when the line runs:
tracepoint = TracePoint.new(:line) do |tp|
tp.binding.receiver.define_singleton_method(:greet) { puts 'Hello world' }
end
tracepoint.enable
greet # => Hello world
And now we have a way to define “variables” inside our tracepoint. Methods and variables aren’t quite the same, and they have slightly different behaviours, but they look close enough that I think we can get away with it.
Turning a token into a value
When we found the value below each arrow, we got back a token from Ripper.lex, which isn’t a value we can assign in a method. But we can turn it into one:
def convert_to_value(token)
case token[:type]
when :on_int
token[:token].to_i
when :on_tstring_content
token[:token]
when :on_ident
eval("#{token[:token]}")
end
end
The biggest crime here is the use of eval to turn a string containing a variable name into a variable. I suspect there’s a neater way to do it by fiddling with bindings, but I have to stop somewhere.
We can drop this into our tracepoint, and our upward assignment operator springs into life:
upwards_assignment = TracePoint.new(:line) { |tp|
…
this_identifiers.each { |var|
arrow_below = …
value_below = …
tp.binding.receiver.define_singleton_method(var[:token]) {
|*args| convert_to_value(value_below)
}
}
…
}
Now when we use our uequals operator, it will create the variable we want.
Putting it all together
We need a couple more tweaks to get this working: we need to define an empty method for ⇑ so it doesn’t throw a NameError, and further fiddling with bindings, but it does basically work. I’ve wrapped it in a Uequals class (like Kevin’s Vequals class), and it works like so:
Uequals.enable
x
⇑
4
puts x # => 4
You can chain instances of the uequals operator:
x
⇑
y
⇑
3
puts x # => 3
puts y # => 3
This relies on a bit of trickery to create an empty placeholder for y just before the method for x is defined, otherwise you get more NameError’s – but it works, and that’s the important thing: There’s more explanation in the source code.
You can also do parallel assignment:
x
y ⇑
⇑ 5
6
puts x # => 5
puts y # => 6
Unfortunately there are still some rough edges, and it starts to break down when you combine it with other assignment operators:
x
⇑
y
⇑
z = 4
puts x # => nil
puts y # => nil
puts z # => 4
I think you could make this example work, but it requires more and more looking ahead, and I’m running out of steam. Minor issues like this aside, I think I can claim to have done what I set out to do: create a working upward assignment operator.
If you want to play with it yourself, I’ve uploaded a complete copy of the code in this post, including some comments and examples:
Being serious, briefly
While creating an upward assignment operator is fun, it’s not really the point of this post. Absolutely nobody, including me, is going to use this code.
This was a learning exercise. I’d already learnt a bit by watching Kevin’s original talk, but actually implementing an operator myself taught me much more.
Most of the code I write is “familiar”: it’s using features I already know, and I have a good idea of what’ll happen before I ever run it. But here, because I was using so many new-to-me features – TracePoint, Ripper, bindings, lexical scope – I learnt a lot in a short amount of time. I wrote something like 100 different scripts, and I only knew what they’d do about half the time. It may not be useful code, but it is useful knowledge.
I really recommend downloading some of the code snippets and playing with it yourself; I think it’s a much better way to learn than just reading about what somebody else has done.
And as always, writing it down on a blog post helped cement this new knowledge. I still don’t understand all of it, but trying to explain what I’ve learned to somebody else helped to find the gaps in my thinking. Writing blog posts remains one of the best ways for me to learn about new programming concepts.